Stream. Что это?
Определим Stream как свободную последовательность элементов, которая не хранит никаких данных и использует коллекции как ресурс. Соответственно Stream не предоставляет непосредственного доступа к данным, а дает возможность применить к ресурсу данных вычислительные операции, которые могут быть выполнены последовательно либо параллельно. Эти вычисления в свою очередь "ленивые" и будут выполнены только после вызова терминальной операции.
Все вместе(ресурс данных, последовательность агрегирующих операций и терминальная операция) это называется stream pipeline.

Stream и параллельные вычисления
В разрезе данной темы для нас важным моментом является как раз возможность выполнять вычисления параллельно. И это не требует от нас ни единой строчки многопоточного кода. Или parallel(), когда мы работаем с готовым stream'ом или parallelStream(), когда создаем его сами.
Но все же интересно, как это работает.
Когда вы запускаем код на многоядерном процессоре, Java 8 "распараллеливает" наш stream, на несколько stream'ов, каждый из которых в отдельном потоке выполняет свою подзадачу и результаты объединяются вместе. За это отвечает наш Fork/Join Framework из прошлого поста.
Пример. Сумма элементов в листе с reduce
Рассмотрим простой пример:
public static int sumReduce(List numbers) {
System.out.println(String.format("%"+ 15 +"s %s", "acc", "elem"));
return numbers.stream()
.reduce(0,
(acc, elem) -> {
System.out.println(String.format("accumulator: %d + %d", acc, elem));
return acc + elem;
});
}
System.out.println(String.format("sum%" + 8 + "s" + ":%" + 6 + "d","",
sumReduce(asList(1, 2, 3, 4))));
acc elem
accumulator: 0 + 1
accumulator: 1 + 2
accumulator: 3 + 3
accumulator: 6 + 4
sum : 10
Последовательное вычисление
Мы воспользовались Stream#reduce:
* @param identity the identity value for the accumulating function
* @param accumulator an function for combining two values
* @return the result of the reduction
*/
T reduce(T identity, BinaryOperator accumulator);

Параллельное вычисление
Теперь вызовем parallelStream():
public static int sumParallelReduce(List numbers) {
return numbers.parallelStream()
.reduce(0,
(acc, elem) -> {
System.out.println(String.format("accumulator: %d + %d", acc, elem));
return acc + elem;
});
}
accumulator: 0 + 4
accumulator: 0 + 2
accumulator: 0 + 1
accumulator: 1 + 2
accumulator: 0 + 3
accumulator: 3 + 4
accumulator: 3 + 7
sum : 10
//класс ReferencePipeline
@Override
public final P_OUT reduce(final P_OUT identity, final BinaryOperator accumulator) {
return evaluate(ReduceOps.makeRef(identity, accumulator, accumulator));
}
//класс ReduceOps
public static <T, U> TerminalOp<T, U>
makeRef(U seed, BiFunction<U, ? super T, U> reducer, BinaryOperator<U> combiner) {
[...]
}
Давайте передадим свой combiner непосредственно через вызов друго метода reduce:
* @param combiner function for combining two values, which must be
* compatible with the accumulator function
*/
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
combiner function for combining two values, which must compatible with the accumulator functionЕще это можно выразить вот так:
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)В нашем случае это означает, что нам нужно правильно смерджить аккумуляторы из разных потоков, т.е. просто их сложить, и можно было оставить все как есть и не заморачиваться, но для наглядности немного переделаем наш код:
public static int sumParallelReduce(List numbers) {
return numbers.parallelStream()
.reduce(0,
(acc, elem) -> {
System.out.println(String.format("accumulator: %d + %d", acc, elem));
return acc + elem;
},
(left, right) -> {
System.out.println(String.format("combiner: %d + %d", left, right));
return left + right;
});
}
accumulator: 0 + 1
accumulator: 0 + 3
accumulator: 0 + 4
accumulator: 0 + 2
combiner: 1 + 2
combiner: 3 + 4
combiner: 3 + 7
sum : 10

Вывод
Stream API дает нам возможность выполнять вычисления параллельно, используя для этого Fork/Join Framework, который выбирает подходящий вариант разбивки задачи и объединения результата. При этом, мы работаем с тем же самым common ForkJoinPool, которые мы использовали в прошлом посте:
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
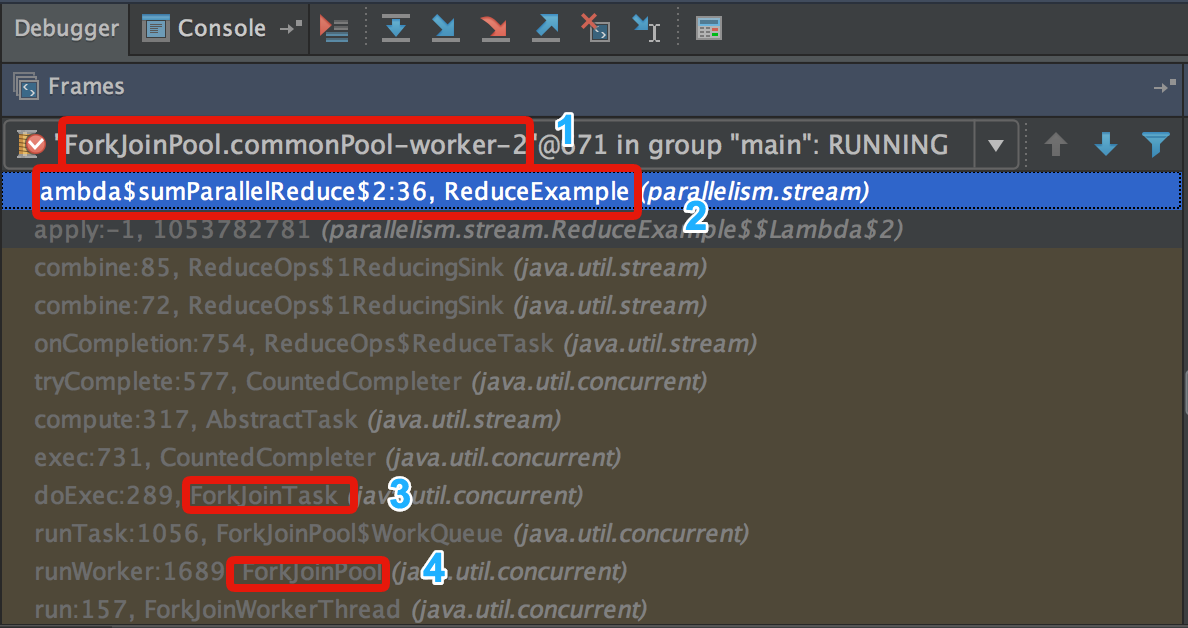
Это мы можем увидеть в дебаггере:
Метериалы:
Java 8 streams API and parallelism
Java 8 parallel streams - an essential trick
Комментариев нет:
Отправить комментарий